树
基本定义和术语
- 树是n个节点的有限集合
- 空树:节点数为0的树
- 非空树:节点数大于0的树
非空树
- 有且仅有一个根节点
- 没有后继的节点称为 叶子节点
- 有后继的节点称为 分支节点
- 除了根节点外,任何一个节点有且仅有一个前驱
- 每个节点可以有0个或多个后继
术语
- 祖先节点:比自己深度低的节点
- 子孙节点:比自己深度高的节点
- 父节点:自己的根节点
- 孩子节点:自己作为根节点的儿子
- 兄弟节点:与自己拥有相同父节点的节点
- 堂兄弟节点:与自己同一层的节点
- 路径:能从上往下前往的两个节点被称为有路径
- 路径长度:经过几条边
- 深度:从上往下数,默认从1开始
- 节点高度:从下往上数
- 数的高度:总过有多少层
- 节点的度:有几个孩子(分之)
- 树的度:各节点的度的最大值
树的性质
- 树的总节点数 = 树的总度数 + 1
- 度为m的树第i层至多有 $m^i -1$ 个节点(i >= 1)
- m叉树第i层至多有 $m^i -1 $个节点(i>=1)
- 高度为h的m叉树之多有 $\frac{(m^h - 1)} { m } -1 $个节点
- 高度为h的m叉树之少有h个节点
- 高度为h,度为m的树之少有h + m - 1个节点
- 具有n个节点的m叉树的最小高度为 $\log_m(n(m-1) + 1)$
- 高度最小的情况:所有节点都有m个孩子
二叉树的定义和基本术语
- 每个节点至多只有两棵子树,且子树有左右之分
特殊的二叉树
满二叉树:每层都是满的。假设高度为3,满二叉树节点就是7个
1
/ \
2 3 <== 这就是满二叉树
/ \ / \
4 5 6 7完全二叉树:满二叉树删除最后x个节点,比如一个完全二叉树高度是3,下面都是完全二叉树
1 1 1
/ \ / \ / \
2 3 2 3 2 3
/ \ / / \ /
4 5 6 4 5 4二叉排序树: 任何一个节点,左子树比它小,右子树比它大
5 5 5
/ / \ / \
3 3 7 3 7 ......好多好多
/ / \ / /
1 1 10 1 6平衡二叉树: 树上任一节点的左子树和右子树的深度之差不超过1
5 👈这是二叉排序树😋 3
/ 但不是平衡二叉树 / \
3 你可以理解为左轻右重 1 5
/ 很不美观,调整后👉
1二叉树性质
- 设非空二叉树中度为0,1和2的节点个数分别为n0, n1, n2,则n0 = n2 + 1(叶子节点比二分支节点多一个)
- 二叉树第i层至多有 $2^{n-1}$ 个节点
- 高度为h的二叉树至多有 $2^h - 1$ 个节点(满二叉树)
完全二叉树性质
- 具有n个(n>0)结点的完全二叉树的高度h为 $\log_2(n + 1)$ 或 $[log_2n] + 1$
- 对于完全二叉树,可以由的结点数n 推出度为0、1和2的结点个数为n0、n1和n2(突破点:完全二叉树最多只会有一个度为1的结点)
二叉树的存储结构
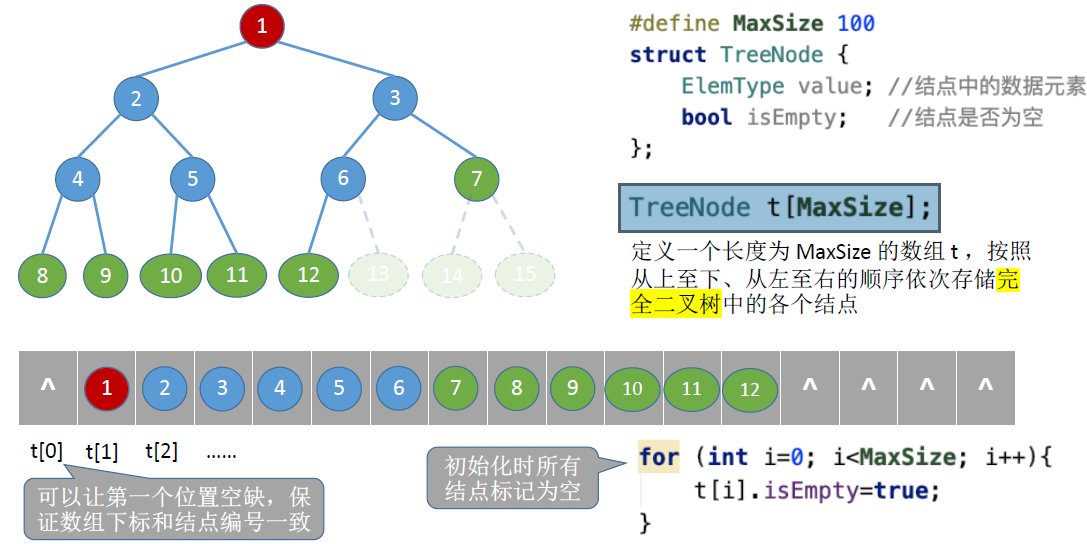
顺序存储
- i的左孩子:2i
- i的右孩子:2i + 1
- i的父节点:i / 2
- i所在的层次:$\log_2(n + 1)$ 或者 $\log_2n + 1$
完全二叉树有n个节点
- 判断i是否有左孩子:2i <= n
- 判断i是否有右孩子: 2i + 1 <= n
- 判断i是否是叶子/分支节点: i > n / 2
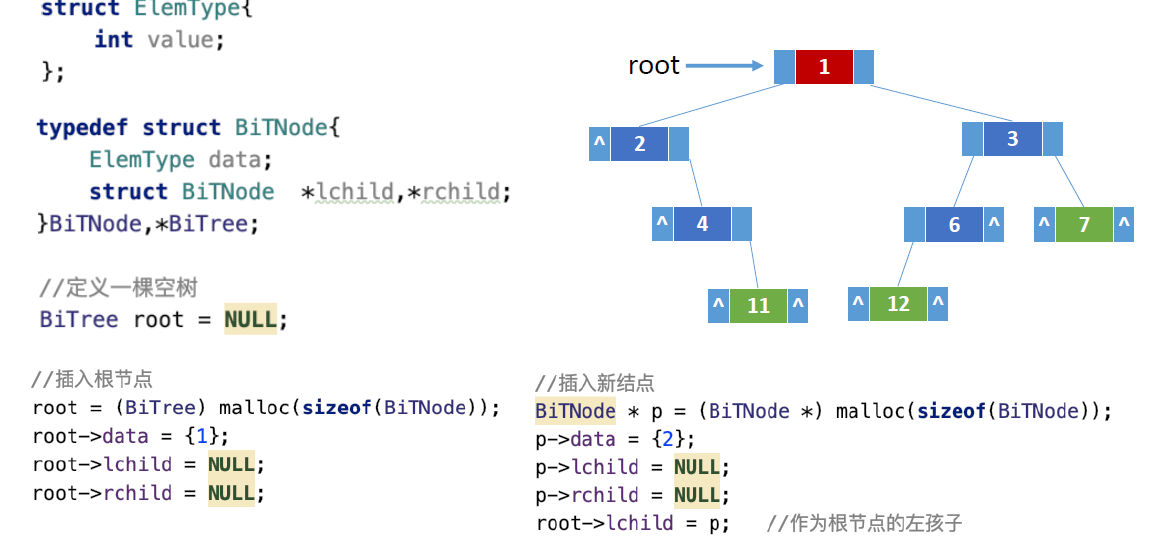
链式存储
- 可以简单找到p节点的左右节孩子,但只能通过从根开始遍历找到p的父节点
- 可以多定义一个父节点指针来方便查找父节点
二叉树遍历
- 层序遍历:基于树的层次特性确定的次序规则
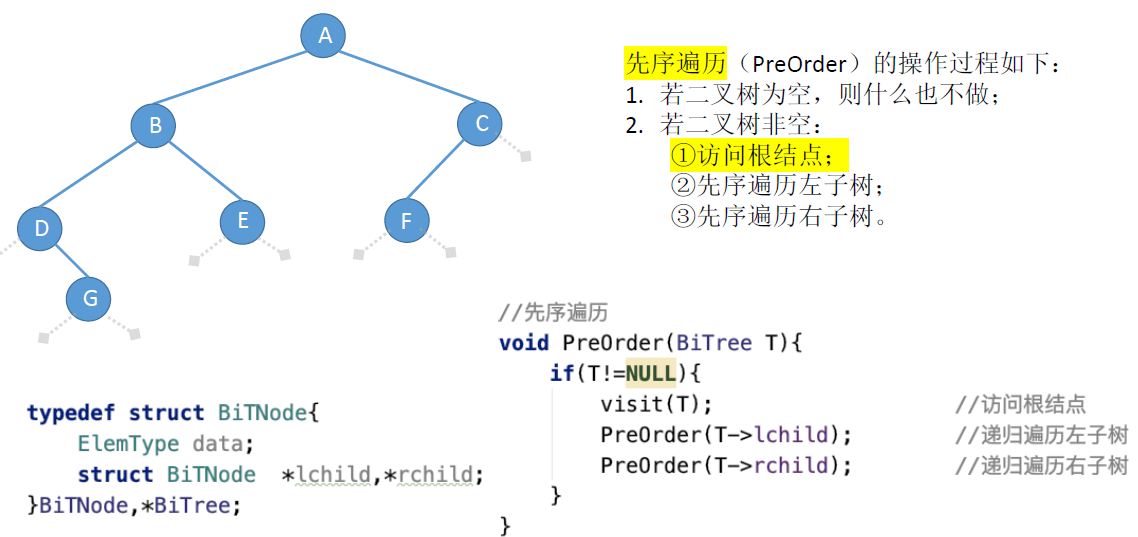
- 前序遍历:根左右
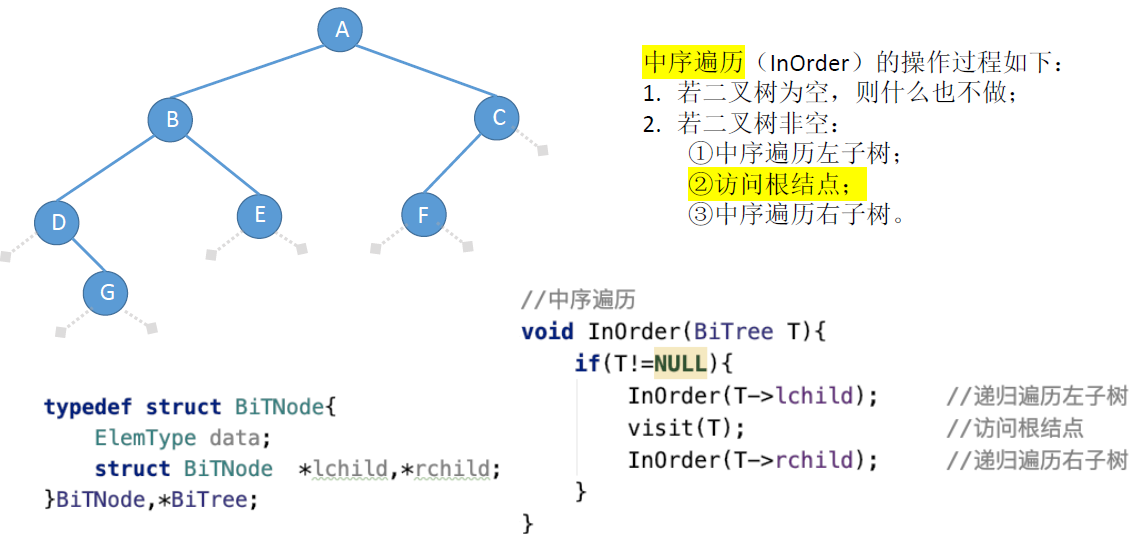
- 中序遍历:左根右
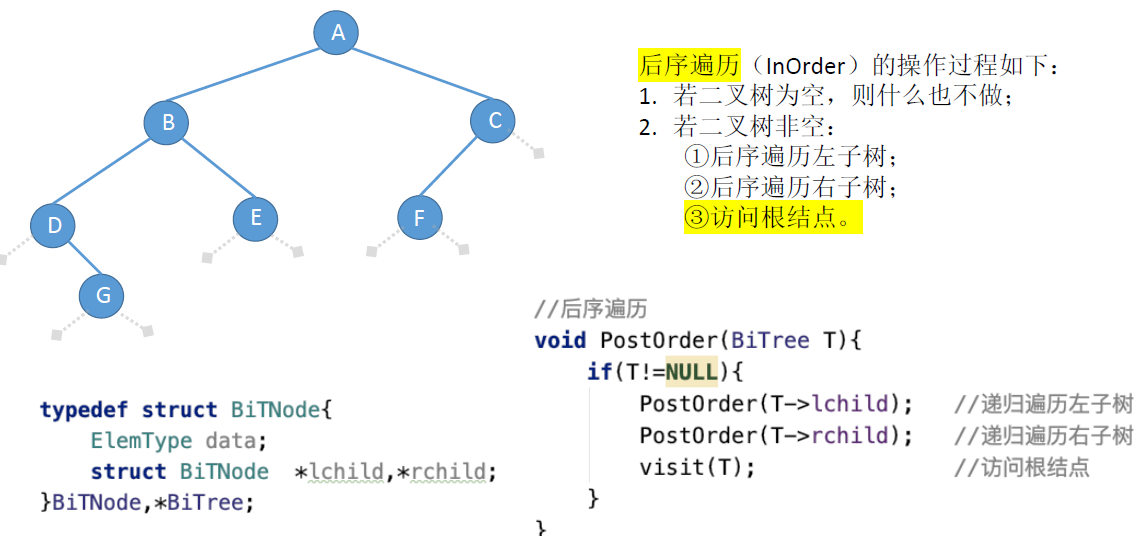
- 后序遍历:左右根
前序遍历
中序遍历
后序遍历
层序遍历
- 初始化辅助队列
- 根节点入队列
- 若队列非空,则队头节点处队,访问该节点,并将左右孩子插入队尾
- 重复第三步,直到队列为空

构造二叉树
- (先序 + 中序) => 唯一的二叉树
- (后序 + 中序) => 唯一的二叉树
- (层序 + 中序) => 唯一的二叉树
二叉排序树
- 二叉排序树,又称二叉查找树
- 一棵二叉树或者是空二叉树,或者是具有如下性质二叉树 左子树节点值 < 根节点 < 右子树节点值
- 中序遍历,可以得到一个递增的有序序列
查找
- 目标值与根节点的值比较
- 相等,则查找成功
- 小于根节点,则在左子树查找,否则在右子树查找
- 查找成功,返回节点指针
- 查找失败,返回NULL
- 递归实现最坏空间复杂度为O(h)
非递归
// 在二叉排序树中查找值为key的结点
BSTNode *BST_Search(BSTree T, int key) {
// 若树空或等于根结点值,则结束循环
while (T != NULL && key != T->key) {
// 小于,则在左子树上查找
if (key < T->key) T = T->lchild;
// 大于,则在右子树上查找
else T = T->rchild;
}
return T;
}递归方式
// 在二叉排序树中查找值为key的结点(递归实现)
BSTNode *BSTSearch(BSTree T, int key) {
if (T == NULL)
// 查找失败
return NULL;
if (key == T->key)
// 查找成功
return T;
else if (key < T->key)
// 在左子树中找
return BSTSearch(T->lchild, key);
else
// 在右子树中找
return BSTSearch(T->rchild, key);
}插入
- 二叉树为空,直接插入节点
- 若关键字k小于根节点,插入左子树,否则插入右子树
// 在二叉排序树插入关键字为k的新结点(递归实现)
int BST_Insert(BSTree &T, int k) {
// 原树为空,新插入的结点为根结点
if (T == NULL) {
T = (BSTree)malloc(sizeof(BSTNode));
T->key = k;
T->lchild = T->rchild = NULL;
// 返回1,插入成功
return 1;
}
// 树中存在相同关键字的结点,插入失败
else if (k == T->key)
return 0;
// 插入到T的左子树
else if (k < T->key)
return BST_Insert(T->lchild, k);
// 插入到T的右子树
else
return BST_Insert(T->rchild, k);
}构造
// 按照 str[] 中的关键字序列建立二叉排序树
void Creat_BST(BSTree &T, int str[], int n) {
// 初始时T为空树
T = NULL;
int i = 0;
// 依次将每个关键字插入到二叉排序树中
while (i < n) {
BST_Insert(T, str[i]);
i++;
}
}删除
- 先搜索找到目标节点
- 如果删除节点是叶节点,直接删除
- 如果只有一棵左子树或右子树,则让节点的子树称为z的父节点的子树
- 如果有两棵子树,令z的直接后继(或直接前驱)代替z,然后从二叉树中删除这个直接后继(或直接前驱)
- 如果是后继,z的右子树最左下节点是右子树最小的节点
- 如果是前驱,z的左子树最右下节点是左子树最大的节点
查询效率分析
- 平均查找长度:各层(层数*层节点个数)相加 / 总节点个数
- 最坏情况:每个节点只有一个分支,树高h = 节点数n。平均查找长度O(n)
- 最好情况:n个节点的二叉树最小高度为 $\log_2n + 1$。 平均查找长度 = O($\log_2n$)
平衡二叉树
定义
- 节点的平衡因子 = 左子树高度 - 右子树高度
- 平衡二叉树节点的平衡因子只可能是 -1, 0, 1
- 只要有任一节点的平衡因子绝对值大于1,就不是平衡二叉树
平均查找长度为O($\log_2n$)
插入
- 查找路径上所有节点都有可能受到影响
- 从插入点往回找到第一个不平衡节点,调整以该节点为根的子树
- 每次调整对象都是最小不平衡子树
- 在插入操作中,只要将最小不平衡子树调整平衡,其他祖先节点都会恢复平衡
- 插入操作导致最小不平衡子树高度+1,经过调整后,高度恢复
调整最小不平衡树
- LL:在A的左孩子的左子树中插入导致不平衡
- RR:在A的右孩子的右子树中插入导致不平衡
- LR:在A的左孩子的右子树中插入导致不平衡
- RL:在A的右孩子的左子树中插入导致不平衡
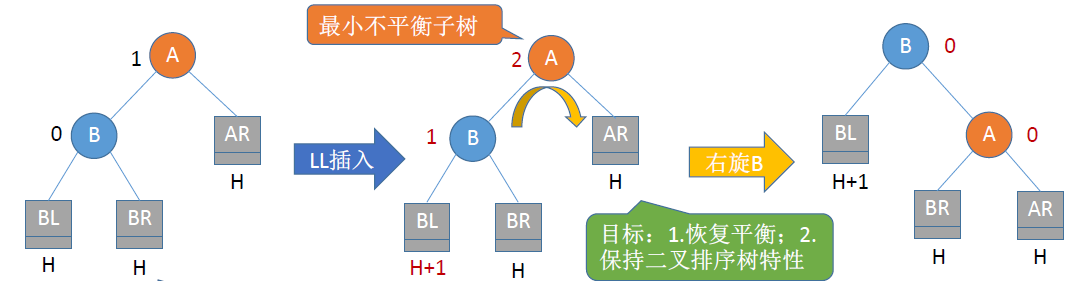
LL平衡旋转
- 由于在A的左孩子的左子树上插入了新节点,A的平衡因子由1增至2,导致以A为根的子树失去平衡,需要一次右旋转操作
- 将A的左孩子B向右上旋转代替A称为根节点
- 将A节点向右下旋转称为B的右子树的根节点
- B的原右子树则作为A节点的左子树
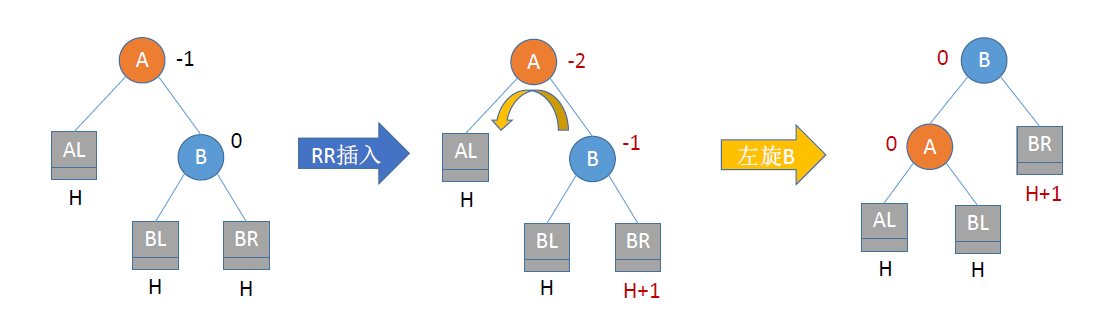
RR平衡旋转
- 由于在节点A的右孩子的右子树上插入了新节点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡,需要一次向左旋转操作
- 将A的右孩子B向左上旋转代替A称为根节点
- 将A节点向左下旋转称为B的左子树的根节点
- B的原左子树作为A节点的右子树
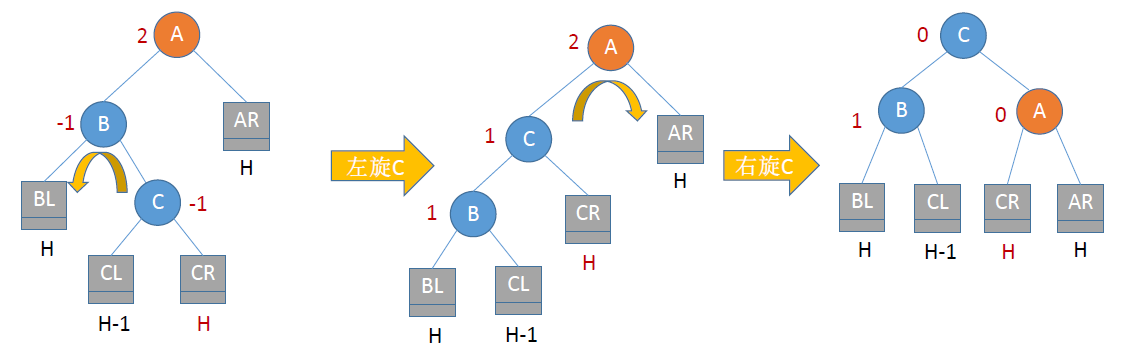
LR平衡旋转
- 由于在A的左孩子的右子树插入了新节点,A的平衡因子由1增至2,导致以A为根的子树失去平衡,需要进行两次旋转操作,先左旋转后右旋转
- 将A节点的左孩子的右子树的根节C点向左上旋转提升至节B节点的位置
- 再把该C节点向右上旋转提升到A节点的位置
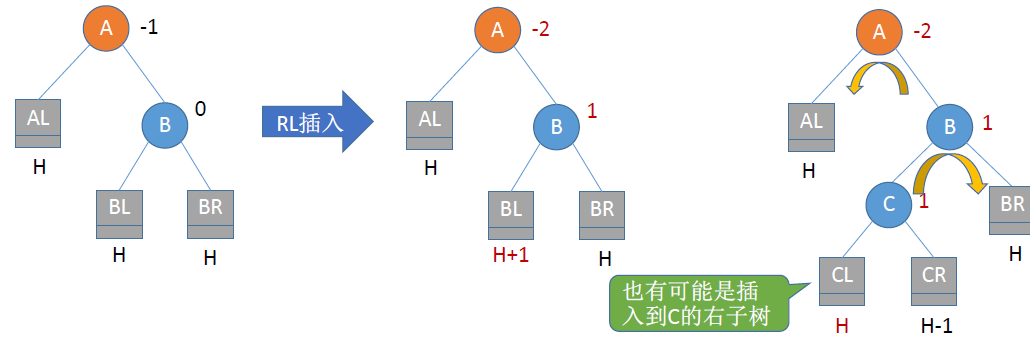
RL平衡旋转
- 由于在A的右孩子(R)的左子树(L)上插入新结点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡,需要进行两次旋转操作,先右旋转后左旋转
- 将A结点的右孩子B的左子树的根结点C向右上旋转提升到B结点的位置
- 然后再把该C结点向左上旋转提升到A结点的位置
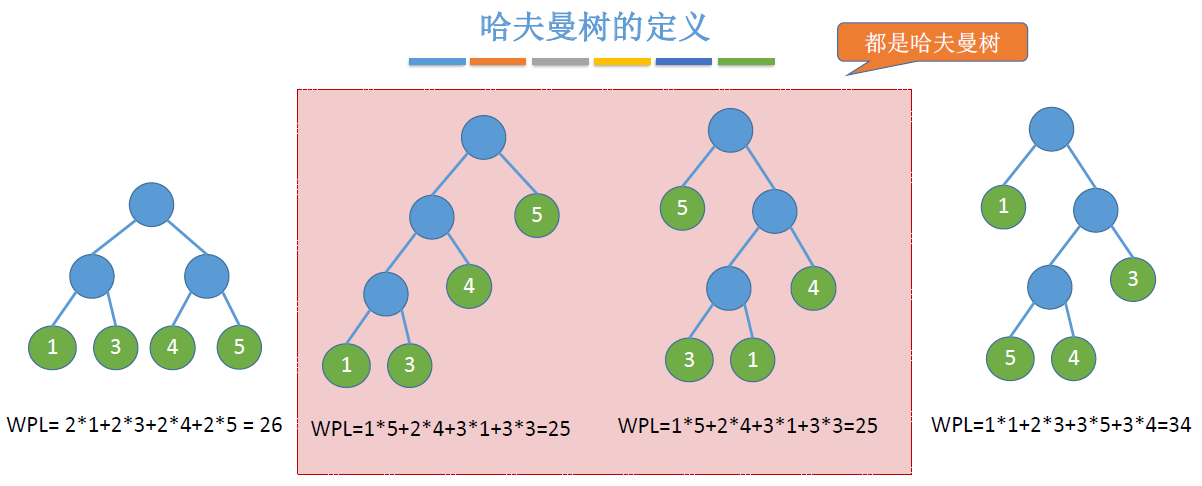
哈夫曼树
定义
- 在含有n个带权叶节点的二叉树中,其中带权路径长度(WPL)最小的二叉树称为哈夫曼树,也称最优二叉树
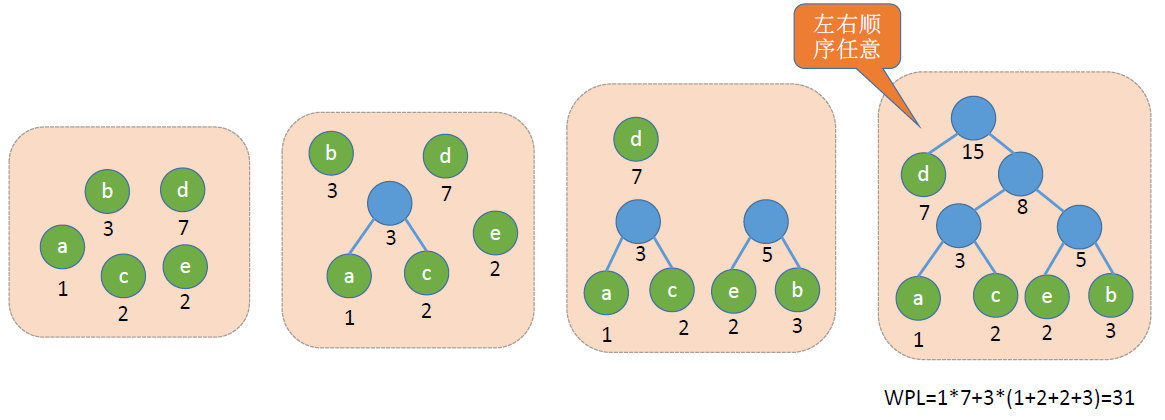
构造
- 将这n个节点分别作为n棵仅含一个节点的二叉树,构成森林F
- 构造一个新节点,从F中选取两棵根节点权值最小的树作为新节点的左右子树
- 将新节点的权值置为左右子树上根节点的权值之和
- 从F中删除刚才选的两棵树,同时将新的到的树加入F中
- 重复2~4,直到F中只剩一颗树为止
特点
- 每个初始节点最终都称为叶节点,且权值越小的节点到根节点的路径长度越大
- 哈夫曼树的节点总数为2n-1
- 哈夫曼树中不存在度为1的节点
- 哈夫曼树并不惟一,但WPL必然相同并最优
哈夫曼编码
- 固定长度编码:每个字符用相等长度的二进制表示
- 可变长度编码:允许对不同字符用不等长的二进制表示
- 若没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码。如果没有前缀编码容易出现歧义
- 由哈夫曼树的到哈夫曼编码:字符集中的每个字符作为一个叶子节点,各个字符出现的频率作为节点的权值,根据之前的方法构建哈夫曼树
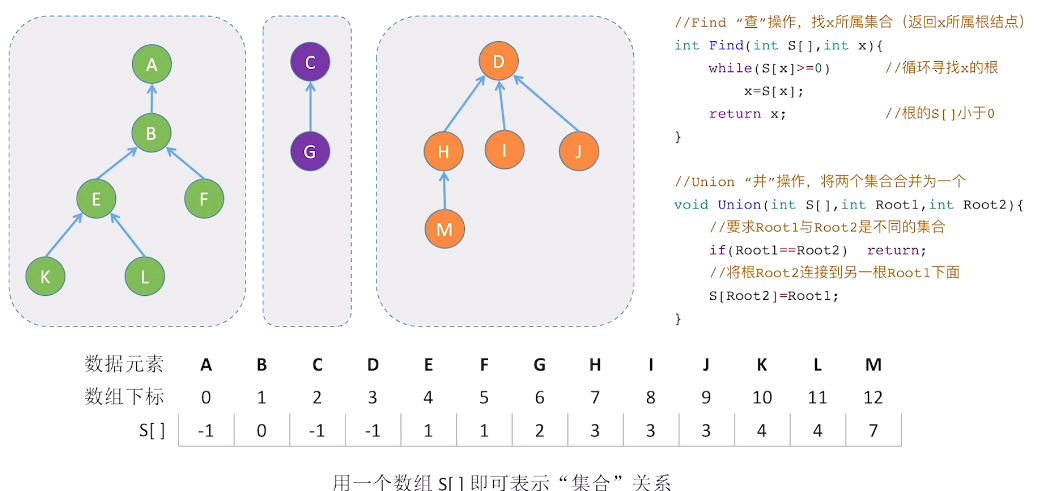
并查集
定义
- 逻辑结构集合的一种具体实现,只进行并和查两种操作
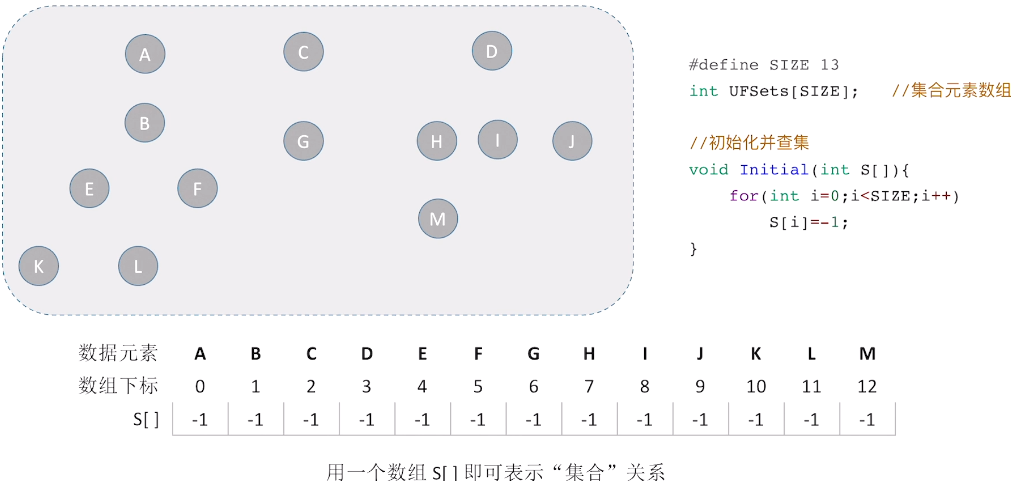
初始化
实际上就是树的双亲表示法,里面的值就是自己对应的根节点下标
并、查
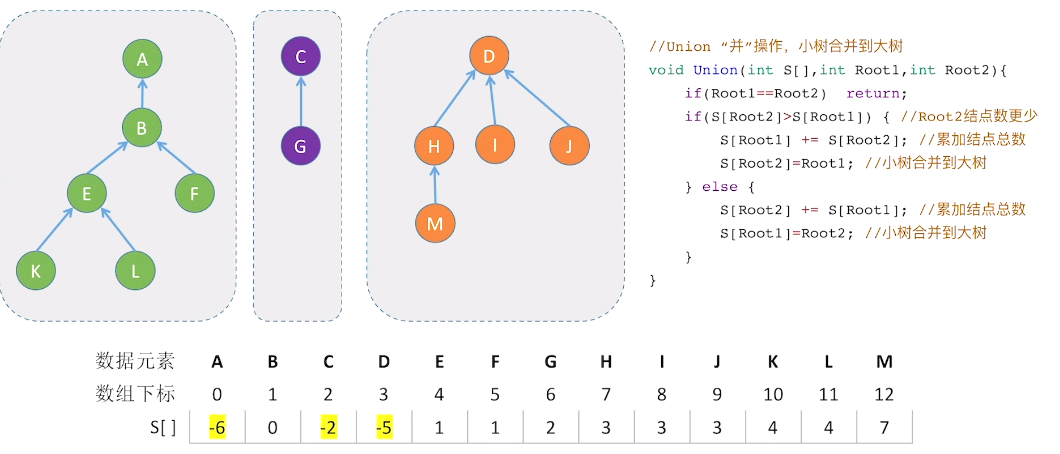
并的优化
- 每次union操作构建树的时候,尽量让树不长高
- 用根节点的绝对值表示树的节点总数
- union操作让小树合并到大树
- 查的最坏时间复杂度变为O($\log_2n$)
压缩路径
- 核心思想就是让树越来越矮
- Find操作先找到根节点,再将查找路径上所有节点都挂到根节点下
// Find "查"操作优化,先找到根节点,再进行"压缩路径"
int Find(int S[], int x) {
int root = x;
// 循环找到根
while (S[root] >= 0) root = S[root];
// 压缩路径
while (x != root) {
// t指向x的父节点
int t = S[x];
// x直接挂到根节点下
S[x] = root;
x = t;
}
// 返回根节点编号
return root;
}- 这样可以让树的高度不超过O($\alpha(n)$)
- O($\alpha(n)$)是一个增长很慢的函数,对于常见的n值,O($\alpha(n)$)通常<=4
- 因此优化后的并查集操作时间开销都比较低